
AI Cambrian Period
DeepSeek suggests that future hardware should improve the accumulation precision (such as FP32) or support configurable accumulation precision; at the same time, Tensor Core should be able to natively support fine-grained quantization, directly receive scaling factors and perform matrix multiplication with group scaling, avoiding frequent data transfer. NVIDIA Blackwell’s microscaling data format is exactly an embodiment of this direction.
DeepSeek has just published a retrospective paper titled “Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures”, and Liang Wenfeng is also one of the authors. This paper deeply analyzes the latest large model DeepSeek-V3 and its AI infrastructure expansion scheme. The practice of DeepSeek-V3 fully demonstrates the great potential of hardware-software co-design in improving the scalability, efficiency and robustness of AI systems.
It is highly recommended to read it carefully!
Here is a quick interpretation of this paper:
The Paper Clearly States at the Beginning: Collaboration between Software and Hardware
The article points out at the very beginning the core contradiction in the development of current large language models (LLMs): the rapid growth of model scale, training data and computing power requirements, but the existing hardware architecture faces severe challenges in memory capacity, computing efficiency and interconnection bandwidth. The success of DeepSeek-V3 precisely proves that “hardware-aware model co-design” is the key to solving these challenges and achieving large-scale, economical and efficient training and inference.
The goal of this paper is not to repeat the technical report of DeepSeek-V3, but to explore the complex interactions between hardware architecture and model design from both perspectives, and provide a practical blueprint for the scalability and cost-effectiveness of future AI systems.
The Secret Revealed of the Core Design of DeepSeek-V3: Three Major Challenges, Solved One by One
The DeepSeek team has carefully designed DeepSeek-V3 around the three core challenges of LLM expansion: memory efficiency, cost-effectiveness, and inference speed.
I. Memory Efficiency: Squeezing Every Bit of Video Memory
First of all, it is the low-precision model (FP8). Compared with BF16, FP8 directly halves the memory occupation of model weights, greatly alleviating the problem of the “memory wall”. This will be elaborated in detail later.
Secondly, the MLA (Multi-head Latent Attention) technology adopted by DeepSeek-V2/V3 compresses the KV representations of all attention heads into a smaller “latent vector” through a jointly trainable projection matrix. During inference, only this latent vector needs to be cached, greatly reducing memory consumption. The comparison data given in the paper shows that the KV Cache per token of DeepSeek-V3 (MLA) is only 70.272KB, while that of Qwen-2.5 72B using GQA is 327.680KB, and that of LLaMA-3.1 405B is as high as 516.096KB. The advantage of MLA is obvious!

In addition, the paper also mentions other valuable methods in the industry, such as GQA/MQA (Grouped/Multi-Query Attention) sharing KV pairs, Windowed KV (Sliding Window), and quantization compression. And it looks forward to the potential of attention mechanisms with linear time complexity (such as Mamba-2, Lightning Attention) and sparse attention.
II. Cost-Effectiveness: MoE Architecture
DeepSeek-V3 adopts the DeepSeekMoE architecture (Mixture of Experts model) that has been verified effective in V2. The core advantage of MoE lies in “sparse activation”: the total number of model parameters can be very large, but only a small part of the expert parameters are activated for each token.
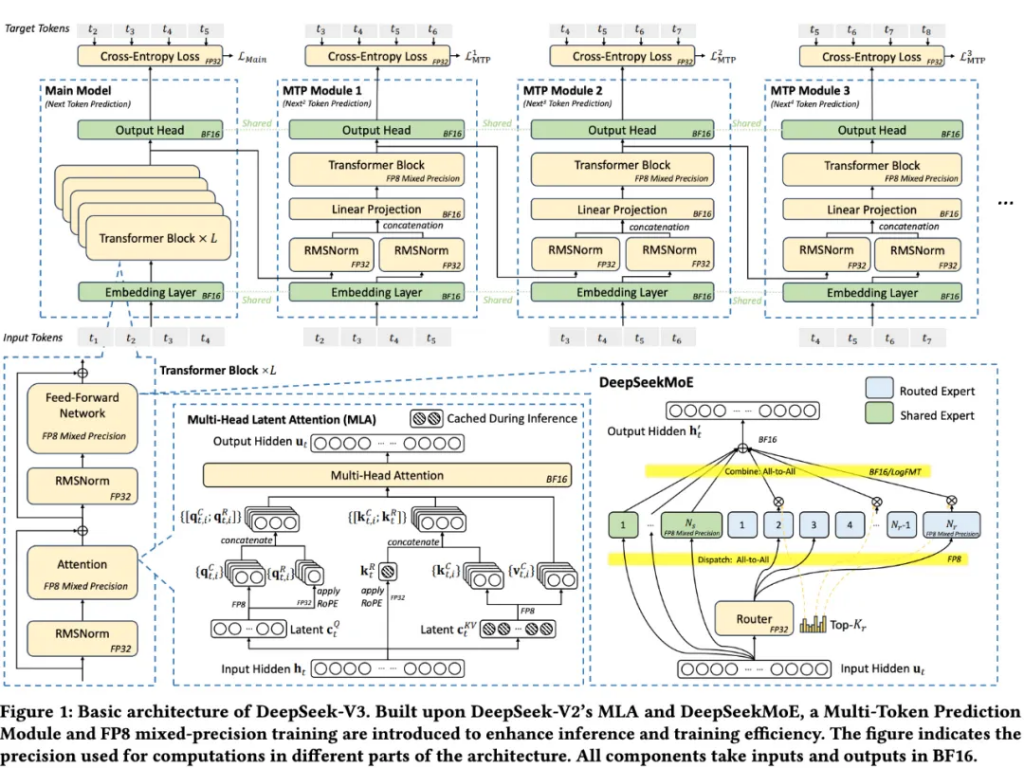
This significantly reduces the training cost. DeepSeek-V2 has 236B parameters, and 21B are activated per token; DeepSeek-V3 is expanded to 671B parameters, and only 37B are activated per token. In contrast, for dense models like Qwen2.5-72B and LLaMA3.1-405B, all parameters are activated during training. From the perspective of computing power consumption comparison, the training cost per token of DeepSeek-V3 is about 250 GFLOPS, which is much lower than 2448 GFLOPS of LLaMA-405B, and even lower than 394 GFLOPS of Qwen-72B.
The characteristic of low-activated parameters of the MoE model also enables good inference speed on the AI SoC of a personal computer (for example, DeepSeek-V2 can reach nearly 20 TPS or even higher on a PC), paving the way for personalized LLM intelligent agents and local deployment. Using the KTransformers inference engine, the complete DeepSeek-V3 model can run at nearly 20 TPS on a server with a consumer-grade GPU (with a cost of about 10,000 US dollars).
III. Inference Speed: Every Second Counts
The DeepSeek model has been designed from the beginning to hide the communication delay through dual micro-batch overlap to maximize the GPU utilization rate. In the production environment, an architecture that separates prefill and decode is also adopted for targeted optimization.
For the MoE model, the All-to-All communication of expert parallelism (EP) is a bottleneck. The paper takes an example to illustrate: if there is one expert per device and 32 tokens are processed at a time, using a CX7 400Gbps InfiniBand network card, the communication time of one EP (dispatch and combine) is about 120.96µs. In the ideal case of dual micro-batch overlap, the total time per layer is about 241.92µs. DeepSeek-V3 has 61 layers, so the total inference time is about 14.76ms, and the theoretical upper limit of TPOT (Time Per Output Token) is about 67 tokens/s. If it is replaced with GB200 NVL72 (900GB/s one-way bandwidth), the communication time is reduced to 6.72µs, and the theoretical TPOT can soar to 1200 tokens/s! This vividly shows the great potential of high-bandwidth interconnection.
Inspired by the work of Gloeckle and others, DeepSeek-V3 has introduced a multi-token prediction (MTP, Multi-Token Prediction) framework. Traditional autoregressive models decode one token at a time, while MTP allows the model to generate multiple candidate tokens at a lower cost and verify them in parallel, similar to speculative decoding. This can significantly accelerate inference. The actual data shows that the acceptance rate of MTP for the second subsequent token is between 80%-90%, increasing the generation TPS by 1.8 times. At the same time, MTP also increases the inference batch size, which is beneficial to improving the EP computing intensity and hardware utilization rate.
Inference models such as OpenAI’s o1/o3 series and DeepSeek-R1, as well as RL processes such as PPO and DPO, are extremely dependent on high token output speed.
Low-Precision Driven Design: Exploration of FP8 Mixed Precision Training
One of the highlights of DeepSeek-V3 is the successful application of FP8 mixed precision training. Before this, there were almost no large models trained based on FP8 in the open source community.
The advantage of FP8 lies in significantly reducing memory occupation and calculation amount. However, it also faces hardware limitations on the Hopper GPU: first, the accumulation precision is limited. When the Tensor Core accumulates in FP8, although the intermediate results are stored in FP22, after right-aligning the product of the 32-bit mantissa, only the highest 13 decimal places are retained for addition, which will affect the training stability of large models; second, the fine-grained quantization overhead is large. For fine-grained quantization such as tile-wise (activation) and block-wise (weight), when part of the results are transferred back from the Tensor Core to the CUDA Core for scaling factor multiplication, a large amount of data transfer and calculation overhead will be introduced.
In this regard, DeepSeek’s suggestion is: future hardware should improve the accumulation precision (such as FP32) or support configurable accumulation precision; at the same time, Tensor Core should be able to natively support fine-grained quantization, directly receive scaling factors and perform matrix multiplication with group scaling, avoiding frequent data transfer. NVIDIA Blackwell’s microscaling data format is exactly an embodiment of this direction.
The DeepSeek team also tried a data type called LogFMT-nBit (Logarithmic Floating-Point Format) for communication compression. It maps the activation values from the linear space to the logarithmic space, making the data distribution more uniform. However, its limitation is that the LogFMT data still needs to be converted back to FP8/BF16 before GPU Tensor Core calculation, and the overhead of log/exp operations and register pressure are relatively large. Therefore, although the experiment verified its effectiveness, it was not actually adopted in the end. They suggest that future hardware natively supports FP8 or a custom precision format compression/decompression unit.
Interconnection Driven Design: Squeezing Every Bit of Bandwidth of H800
The NVIDIA H800 SXM nodes used by DeepSeek-V3 have a reduced NVLink bandwidth (from 900GB/s of H100 to 400GB/s). To make up for this deficiency, each node is equipped with 8 400G InfiniBand CX7 NICs.

In terms of hardware-aware parallel strategies, DeepSeek avoids using tensor parallelism (TP) during training due to the limited NVLink bandwidth, and it can be selectively used during inference; the DualPipe algorithm is adopted to overlap the calculation and communication of Attention and MoE to enhance pipeline parallelism (PP); and 8 IB NICs are used to achieve an All-to-All communication speed of over 40GB/s to accelerate expert parallelism (EP).
In terms of model co-design, due to the huge difference in bandwidth between the NVLink (effective about 160GB/s) of H800 and the IB NIC (effective about 40GB/s), DeepSeek-V3 has introduced a TopK expert selection strategy of Node-Limited Routing: divide 256 routing experts into 8 groups, with 32 experts in each group deployed on a single node, and ensure from the algorithm that each token is routed to at most 4 nodes. This alleviates the IB communication bottleneck.
Regarding the integration of Scale-Up and Scale-Out, the current limitation is that the GPU SM needs to process network messages and forward data through NVLink, consuming computing resources. DeepSeek suggests that future hardware should integrate a unified network adapter, a dedicated communication coprocessor, a flexible forwarding/broadcasting/Reduce mechanism, hardware synchronization primitives, dynamic NVLink/PCIe traffic priority, I/O Die Chiplet integrated NIC, and CPU-GPU Scale-Up domain interconnection.
Large-Scale Network Driven Design: Multi-Plane Fat-Tree
DeepSeek-V3 has deployed a multi-plane fat-tree (MPFT, Multi-Plane Fat-Tree) Scale-out network during training. Each node has 8 GPUs + 8 IB NICs, and each GPU-NIC pair belongs to an independent network plane.
The advantages of MPFT include: as a subset of the multi-rail fat-tree (MRFT), it can utilize NCCL optimization; it is cost-effective, and a two-layer fat-tree can support more than ten thousand endpoints; the traffic of each plane is isolated, and the congestion of a single plane does not affect others; the two-layer topology has lower latency and better robustness. Performance analysis shows that its All-to-All communication and EP scenario performance are very close to those of the single-plane MRFT, and the indicators of training DeepSeek-V3 on 2048 GPUs are almost the same.
In terms of low-latency networks, the latency of IB is better than that of RoCE, but IB is costly and the switch port density is low. Suggestions for improving RoCE include: dedicated low-latency RoCE switches, optimized routing strategies (such as adaptive routing), and improved traffic isolation/congestion control mechanisms. At the same time, DeepSeek also uses the InfiniBand GPUDirect Async (IBGDA) technology to reduce network communication latency.
Outlook on Future AI Hardware Architecture
At the end of the paper, the DeepSeek team puts forward more macroscopic thinking on future AI hardware design based on practical experience:
- Robustness Challenges: To deal with problems such as interconnection failures, single hardware failures, and silent data corruption, hardware needs to integrate advanced error detection mechanisms and provide diagnostic tools.
- CPU Bottleneck and Interconnection: Solve the problems of PCIe bandwidth bottleneck, high memory bandwidth requirements, CPU single-core performance and the number of cores, and it is recommended to directly interconnect the CPU and GPU or integrate them into the Scale-up domain.
- Towards an AI Intelligent Network: Develop silicon photonics, advanced end-to-end congestion control, adaptive routing, efficient fault-tolerant protocols and dynamic resource management.
- Memory Semantic Communication and Order Issues: Hardware should support built-in memory semantic communication order guarantees (such as acquire/release semantics), and eliminate the sender-end fence.
- In-Network Computing and Compression: Optimize the dispatch and combine of EP, and natively integrate compression technologies such as LogFMT.
- Memory-Centered Innovation: Promote DRAM stacking accelerators and System-on-Wafer (SoW) technology.

Leave a comment