
https://arxiv.org/abs/2505.04519
In a remarkable technological feat, Huawei has successfully trained a large-scale model with a staggering 718 billion (718B) parameters on its Ascend domestic computing power platform. This accomplishment allows Huawei to break free from its reliance on NVIDIA’s technology in the training of such models.
Previously, training trillion-parameter models was fraught with numerous challenges. Load balancing was a major issue, as was the significant communication overhead and low training efficiency. However, Huawei’s Pangu team, which includes Noah’s Ark Lab and Huawei Cloud, has managed to overcome these obstacles.
Overcoming Challenges in Model Training
The path to training large-scale models is filled with four major hurdles. Firstly, there is the optimization of the architecture parameters. The team had to explore and determine the optimal configuration among numerous parameter combinations, designing a large-scale Mixture of Experts (MoE) architecture that is well-suited for the Ascend NPU to ensure efficient utilization of computing resources.
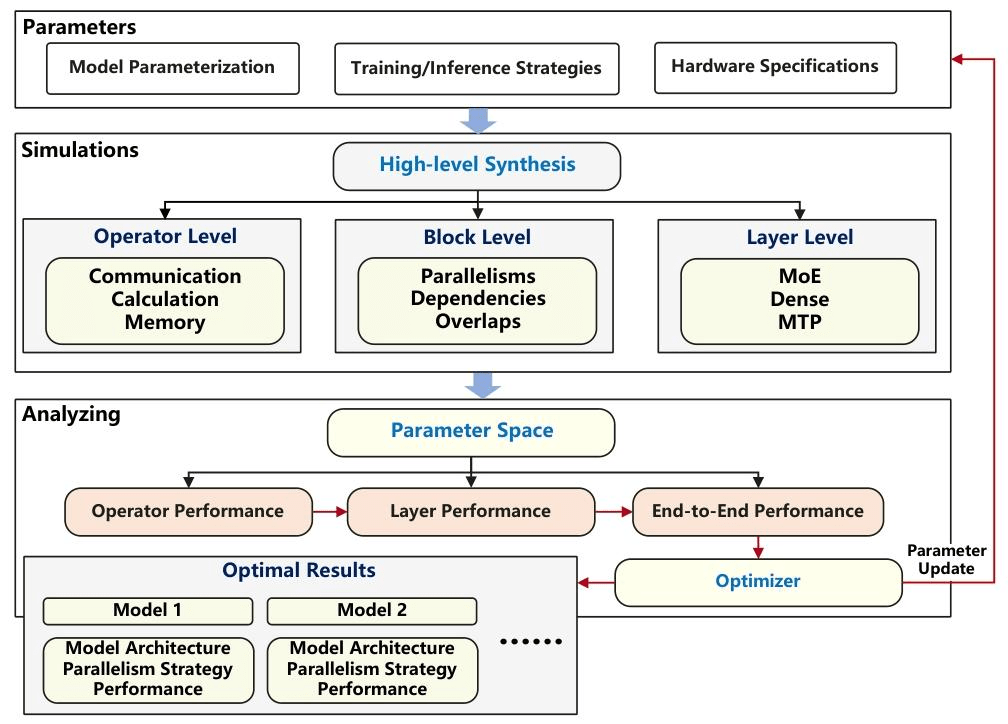
Secondly, the dynamic load balancing challenge requires the routing mechanism to intelligently distribute tasks. If the task distribution among experts is uneven, it will lead to a “wooden barrel effect,” reducing the training efficiency and potentially causing abnormal model convergence, which in turn affects the final performance.
The third obstacle is the bottleneck in distributed communication. At the scale of nearly a trillion parameters, the transfer of tokens among different computing nodes by experts generates a huge communication overhead. This “communication wall” problem is a key factor limiting the training efficiency.
Finally, the complexity of hardware adaptation requires the full-stack optimization of algorithm design, software framework, and hardware characteristics. This is to achieve deep synergy between the MoE algorithm and the Ascend NPU and other dedicated AI accelerators, fully unleashing the computing potential of the hardware.
Innovative Solutions by Huawei
Huawei’s technical report details how the team addressed these issues from various aspects such as model architecture, MoE training analysis, and system optimization.
In terms of MoE structure selection and Ascend affinity structure optimization, the team conducted pilot experiments and determined the paradigm of fine-grained experts combined with shared experts. When selecting the model, multiple factors were considered. In terms of computing and memory access affinity, by increasing the hidden size in the model while reducing the number of activation parameters, the amount of computation in the model can be increased, and the memory access can be reduced. This improves the utilization rate of computing power during model training and the throughput during inference. In terms of multi-dimensional parallel affinity, an exponential number of experts is adopted, achieving a super fusion parallel mode of TP8×EP4. The TP-extend-EP technology is applied to avoid the efficiency drop of operators such as MatMul caused by the fine-grained expert division in TP. At the same time, the group AllToAll communication technology is used to reduce the communication overhead generated by EP. In terms of the DaVinci architecture affinity, the tensor is aligned according to 256, making it perfectly match the 16×16 matrix computing unit and fully releasing the computing power of the Ascend NPU. In terms of pipeline orchestration affinity, technologies such as PP (pipeline parallelism), VPP (variable pipeline parallelism), and empty layers are adopted to achieve load balancing between PP and VPP and reduce the situation of computing resource idleness (empty bubbles).
In model structure simulation, according to the adaptation characteristics of the hardware, the team greatly adjusted the selection range of model parameters, reducing the originally huge parameter search space to about 10,000. To accurately understand the performance limits of different models, the team developed a special modeling and simulation tool. This tool splits the model structure, the strategies adopted during runtime, and the hardware system into small parameters. By simulating the computing, data transmission, and reading operations at the operator, Block, and Layer levels, the overall performance of the model from start to finish can be calculated. After comparing with the actual test data, it is found that the accuracy of this simulation tool can reach more than 85%.
Advanced Training Analysis
When training the MoE model, compared with the ordinary dense model, the problem of load imbalance is particularly troublesome. It’s like a group of people working, where some are extremely busy while others are idle, which will inevitably lead to low efficiency. To solve this problem, the scientific research community has proposed various auxiliary loss functions from the algorithm perspective, which focus on different equilibrium scopes. For example, there were early sequence-level equilibrium auxiliary losses, and the DP-Group (i.e., global batch size) equilibrium auxiliary loss proposed by Tongyi Qianwen.
The team also developed a brand-new EP group load balancing loss algorithm. Compared with the traditional micro-batch auxiliary loss, it does not overly demand absolute equilibrium in local task allocation, avoiding “overcorrection.” Compared with the DP group’s equilibrium loss, it consumes fewer resources during data transmission, saving a lot of communication costs. And in terms of the degree of constraint on the task volume of experts, it is a more balanced solution between the two.
To verify the effect of this new algorithm, the team conducted ablation experiments on a pilot MoE model with a total of 20 billion (20B) parameters. In order to deal with the “wooden barrel effect” of uneven expert loads, MoE can use the drop-and-pad method to improve training throughput. The team first compared the performance of drop-and-pad and dropless under different total numbers of experts on a 20B pilot MoE. The results show that dropless is always better than the drop-and-pad solution. And this performance gap will further widen as the number of experts increases and the model parameters become larger. Therefore, the dropless solution was adopted when training the Pangu Ultra MoE and focused on optimizing the training efficiency under this strategy.
System Optimization and Experimental Results
In a large-scale computing cluster composed of more than 6000 Ascend NPUs, the computing power utilization rate (MFU, Model FLOPs Utilization) of the model reached 30.0%, an increase of 58.7% compared with before optimization. The team used a model simulation system that can simulate the entire process to repeatedly test and find the best parallel computing solution. The final determined solution is: 16-way pipeline parallelism, 8-way tensor parallelism, 4-way expert parallelism, 2-way virtual pipeline parallelism, and 48-way data parallelism.
To solve the communication bottleneck in parallel expansion, the team designed two main technologies. The first is Hierarchical EP Communication. Compared with in-machine communication, cross-machine communication has a lower bandwidth. The team adopted hierarchical EP communication to reduce the cross-machine communication volume. Specifically, cross-machine Allgather communication is used to synchronize all tokens to the in-machine, and then the tokens are sorted in the in-machine and in-machine AlltoAll communication is used to redistribute the tokens. Both in-machine communication and inter-machine communication can be masked by the forward and backward communication masking technology. The effect of hierarchical EP communication on reducing the cross-machine communication volume can be seen from the comparison of communication volumes.
The second is the Adaptive Pipe Overlap Mechanism. Even with the hierarchical EP communication strategy, the time-consuming proportion of EP communication is still high. Most of the EP communication in the forward and backward directions has a dependency relationship with the calculation. The natural masking strategy will expose most of the EP communication. If self-masking strategies such as the general calculation fusion operator are adopted, it will inevitably reduce the calculation efficiency. Therefore, the team adopted an adaptive forward and backward masking strategy based on VPP scheduling to achieve forward calculation masking of backward communication and backward calculation masking of forward communication. The core design includes: using the independent characteristics of the communication link bandwidth between the machine and in the machine to achieve mutual masking of in-machine communication and inter-machine communication, and using the effective arrangement of operators to alleviate the host bound, and separating the expert backward dw calculation from the dx calculation for more fine-grained masking.
When optimizing the video memory, the team adopted a new calculation method. Instead of using the traditional full re-computation, the fine-grained modules such as MLA, Permute, and activation functions are re-calculated to avoid additional calculation consumption. At the same time, the Tensor Swapping technology is used to transfer the activation values that are not cost-effective to re-calculate to the CPU first and retrieve them in advance when reverse calculation is required, making more efficient use of the NPU memory.
In the process of building the training data set, the team implemented strict data quality control and emphasized the diversity, complexity, and comprehensiveness of the corpus. Special marker symbols are introduced for long-chain thinking samples to structurally separate the inference trajectory from the final answer. In the post-training stage, the instruction fine-tuning strategy is adopted, and the data covers a wide range of fields, including general question answering, text generation, semantic classification, code programming, mathematical logic reasoning, and tool use. In particular, the ratio of inference samples to non-inference samples is set to 3:1, further improving the inference performance.
The experiment shows that the dialogue version of Pangu Ultra MoE demonstrates excellent competitiveness in multiple fields, performing comparably to DeepSeek-R1 on most benchmarks. For example, it shows excellent comprehension ability in general understanding tasks (such as 94.8 points in CLUEWSC and 91.5 points in MMLU) and performs outstandingly in high-difficulty tests such as mathematical reasoning and code generation (such as 81.3 points in AIME2024 and 81.2 points in MBPP+).
The team also conducted an analysis of the expertise of the experts in Pangu Ultra MoE. In different tasks, the tokens in the same network layer will be preferentially routed to different experts, and there is a significant task difference in the degree of expertise specialization. This confirms that Pangu Ultra MoE has formed significant expert differentiation, which not only enhances the expressive ability of the model but also provides key support for its excellent performance.
In conclusion, Huawei’s breakthrough in the Pangu Ultra MoE technology marks that China’s domestic computing power platform has entered the world’s leading position in the field of AI large model training. It demonstrates the strong strength of Chinese technology companies in the global AI competition, enabling them to shift from following to running alongside and even leading the way. In the future, with the continuous iteration of technology and the expansion of application scenarios, Pangu Ultra MoE will inject strong impetus into the intelligent transformation of various industries, contributing more “Chinese wisdom” to the progress of human science and technology.

Leave a comment